DeepSeek-R1 has surpassed Llama 4 in reasoning ability, and the training cost is only equivalent to the annual salary of a single Meta executive.
DeepSeek is popular.
In January 2025, China start-up DeepSeek successively released two major models, DeepSeek-V3 and DeepSeek-R1, setting off a huge wave in the industry.
The company's large model product, established in 2023, not only refreshes industry awareness with performance indicators close to OpenAI, but also subverts Silicon Valley's inherent logic of investment in AI R & D with an ultra-low training cost of US$5.5 million.According to a test report by Scale AI, a leading company in the field of AI data services, DeepSeek-V3 has ranked with the top models in the United States in many core indicators.
On January 24, Alexander Wang bluntly said in an exclusive interview that the breakthrough of this China company revealed that "when Silicon Valley is addicted to capital carnival, Oriental engineers are rewriting the rules of the game with more sophisticated system optimization capabilities."This view is confirmed on the anonymous workplace platform Teamblind: a Meta engineer posted that the company's top management has conducted an urgent research on DeepSeek's technical path. Its open source model DeepSeek-R1 has surpassed Llama 4 (the generative AI model developed by Meta) in terms of reasoning capabilities, and the training cost is only equivalent to the annual salary of a single Meta executive, which has plunged the Silicon Valley giant, which invests billions of dollars in R & D budgets every year, into strategic anxiety.InvalidParameterValue
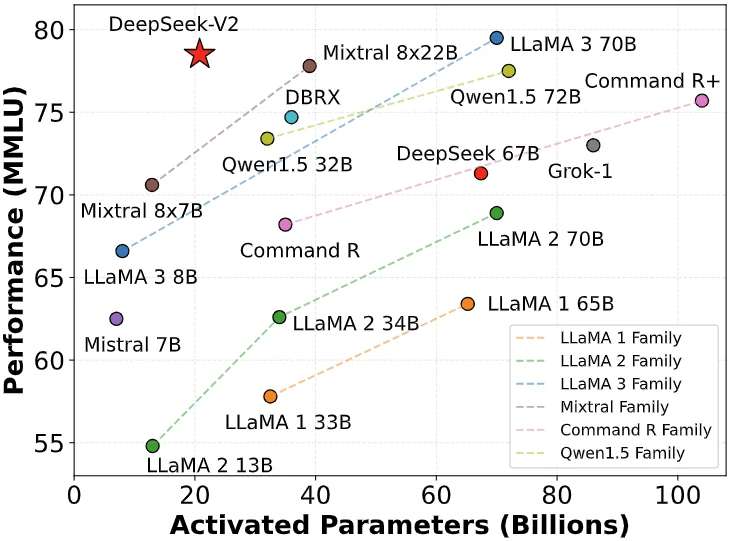
Technical details show that after DeepSeek-V3 was open source on December 27, 2023, it won the first place in the LMSys Chatbot Arena rankings, and its comprehensive performance surpassed internationally renowned models such as Llama 2- 70B and Falcon-180B.What's even more striking is that this model is 80% lower in cost per token than similar products. This cost-effectiveness is further enhanced on DeepSeek-R1, which will be released on January 20, 2024.
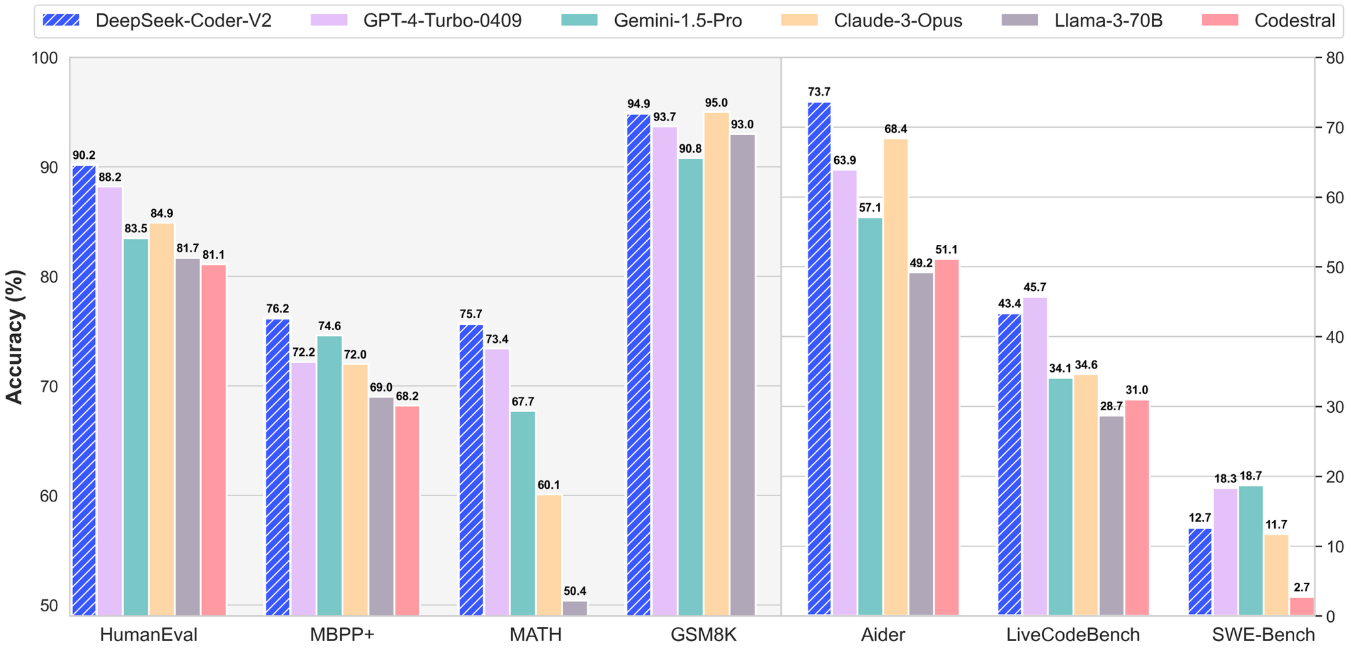
According to independent evaluation by Stanford University's AI Laboratory, the R1 model surpasses GPT-4 Turbo in difficult tasks such as code generation and mathematical reasoning. Its style control ability ranks first with Anthropic's top closed-source model o1, and the API call cost is only 3% of the latter.This technical feature of "simultaneous realization of performance jump and cost compression" directly shakes the industry's belief in the "determinism of computing power scale."InvalidParameterValue
The impact of the industry is rapidly emerging in the capital market.
On January 24, Nvidia's share price fell 3.12% in a single day, the largest decline in three months. The market was worried that the computing power optimization capabilities of China AI companies would weaken their dependence on cutting-edge chips.This sentiment resonates with the recent statement made by Microsoft, the largest institutional investor in OpenAI. Its chief technology officer Kevin Scott admitted at the Davos Forum that the current AI competition has shifted from purely pursuing parameter quantities to "a composite of algorithm innovation and engineering efficiency. competition."
Geoffrey Hinton, Nobel Prize winner and the "father of deep learning", further pointed out in a recent interview that China's huge STEM talent pool (about 5 million graduates each year, far exceeding the 800,000 in the United States) is being transformed into engineering practice advantages, and this systematic ability may backfire the technology blockade strategy.InvalidParameterValue
The reaction of the Silicon Valley venture capital community to this round of shocks has been divided.Marc Andreessen, founder of A16z (Silicon Valley's top venture capital with more than US$35 billion in assets under management), hailed DeepSeek-R1 as a "milestone in the open source community," while Sequoia Capital analysts warned that if industry leaders maintain their current capital consumption rate (annual hardware spending by U.S. AI companies is expected to reach US$500 billion in 2028), the return on investment cycle will face a severe test.
Deep in the industry, this shock wave is raising fundamental questions about the AI development paradigm.Joint research by Stanford University and Epoch AI (a research institute focusing on AI technology prediction) has predicted that the training cost of top models will exceed the $1 billion threshold by 2027.

However, in-depth practice shows that by improving the MoE (Hybrid Expert) architecture, optimizing the data cleaning process, and innovating distributed training strategies, it is entirely possible to achieve performance breakthroughs within a limited budget.This kind of "actuarial innovation" poses a dual challenge to technology giants such as Meta and Google that rely on massive resources: they must not only respond to the sudden attacks of latecomers on their technical routes, but also prove to investors the need for hundreds of billions of investment.As Wall Street analyst "THE SHORT BEAR" warned on Platform X: "When $55 million can build a top model, the entire AI industry's valuation system needs to be restructured."











