"The most powerful model" changes hands! Claude 3 first surpasses GPT-4 to reach first place
This week, Claude 3 Opus, a subsidiary of artificial intelligence startup Anthropic, surpassed GPT-4 for the first time in the latest ranking of Chatbot Arena, a website that tests and compares the effectiveness of different artificial intelligence models, and ranked first.
As is well known, the GPT-4 under OpenAI is currently the world's top large model (LLM), but just this week, tests showed that the GPT-4's dominant position has been taken away.
This big model that surpasses GPT-4 is called Claude 3.
This week, Claude 3 Opus, a subsidiary of artificial intelligence startup Anthropic, surpassed GPT-4 for the first time in the latest ranking of Chatbot Arena, a website that tests and compares the effectiveness of different artificial intelligence models, and ranked first.
In early March, Aerospace announced the launch of the Claude 3 major model series. This series includes three models, from weak to strong, namely Claude 3 Haiku, Claude 3 Sonnet, and Claude 3 Opus. In the latest ranking of Chatbot Arena, all three major models of the Claude 3 series have reached the top 10.
Previously, according to Anthropic, its most intelligent model, Claude 3 Opus, outperformed its peers on most common evaluation criteria for artificial intelligence systems, including undergraduate level expert knowledge (MMLU), graduate level expert reasoning (GPQA), and basic mathematics (GSM8K). Official statement: "The Claude 3 Opus demonstrates near human level understanding and fluency in complex tasks."
At that time, Anthropic stated that Claude 3 had already shown performance close to or better than GPT-4 or Gemini 1.0 in multiple indicators. The results of this third-party test once again support the statement made by Antiopic.
Chatbot Arena was launched in May last year and was created by the Large Model Systems Organization (LMYSY Order). LMYSY Org is an open research organization founded by students and teachers at the University of California, Berkeley. The purpose of creating Chatbot Arena is to help artificial intelligence researchers and professionals understand how two different artificial intelligence LLMs perform when challenged with the same prompts.
Chatbot Arena is a crowdsourcing platform, which means anyone can conduct testing on it. On the chat page of Chatbot Arena, there are up to 74 different AI models, including the Claude 3 series, OpenAI's GPT-4, Google's Gemini, and Meta's Llama 2, among others.
When a user is conducting a test, the system will require the user to enter a question in the prompt box at the bottom. Then there will be two anonymous model driven chatbots to answer user questions, these two models are simply labeled as Model A and Model B.
After reading two answers, the system will ask the user to give a review. Users can choose which one is better, give them equal evaluations, or indicate that they don't like both. After submitting the rating, the system will inform the user of the big model that drove the two chatbots earlier.
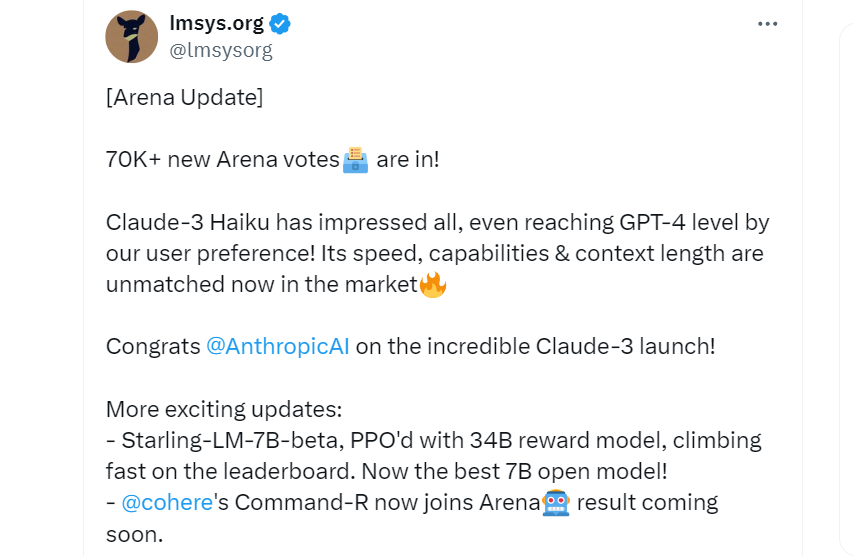
LMYSY Org will count the votes submitted by website users, and then summarize the total number on the leaderboard to display the performance of each LLM. It is understood that since its launch, more than 400,000 users have become judges for Chatbot Arena, and the latest round of rankings has attracted 70,000 users to join.
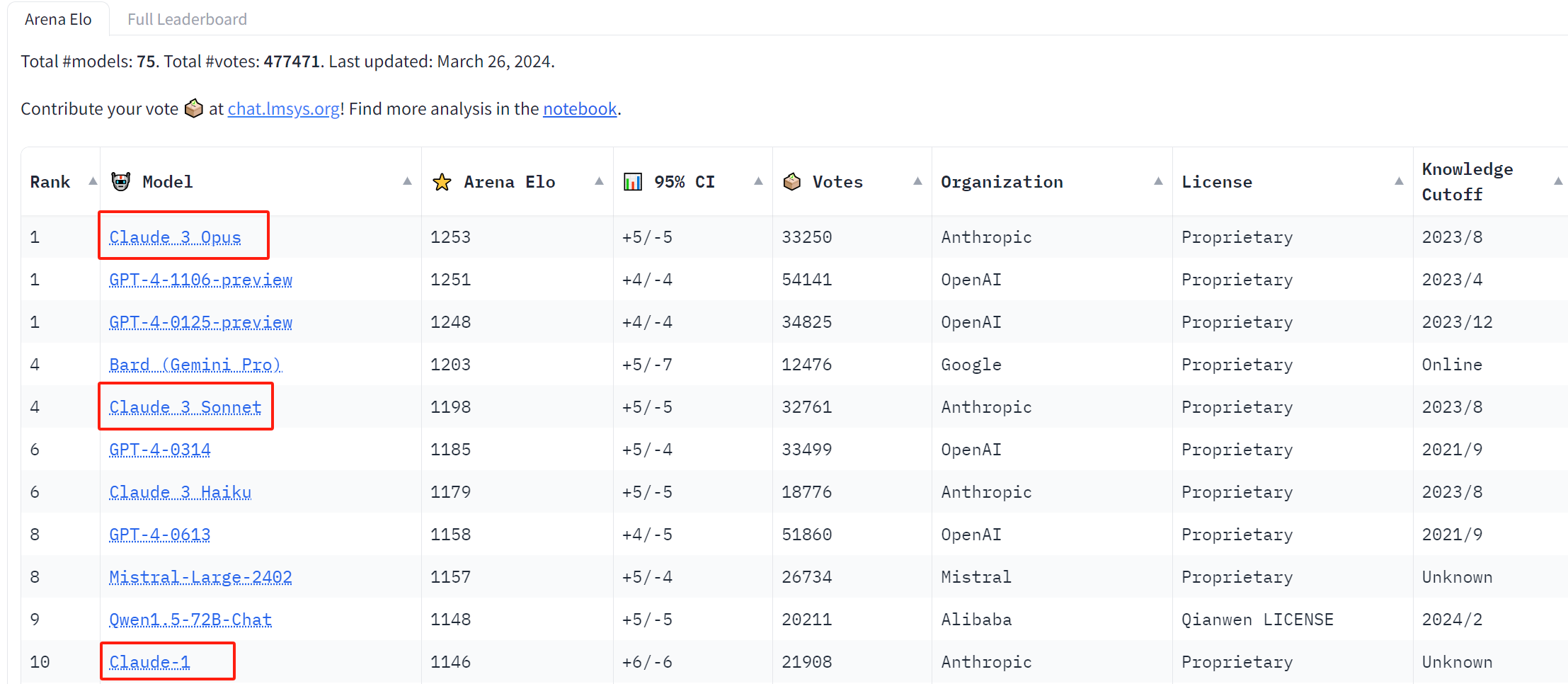
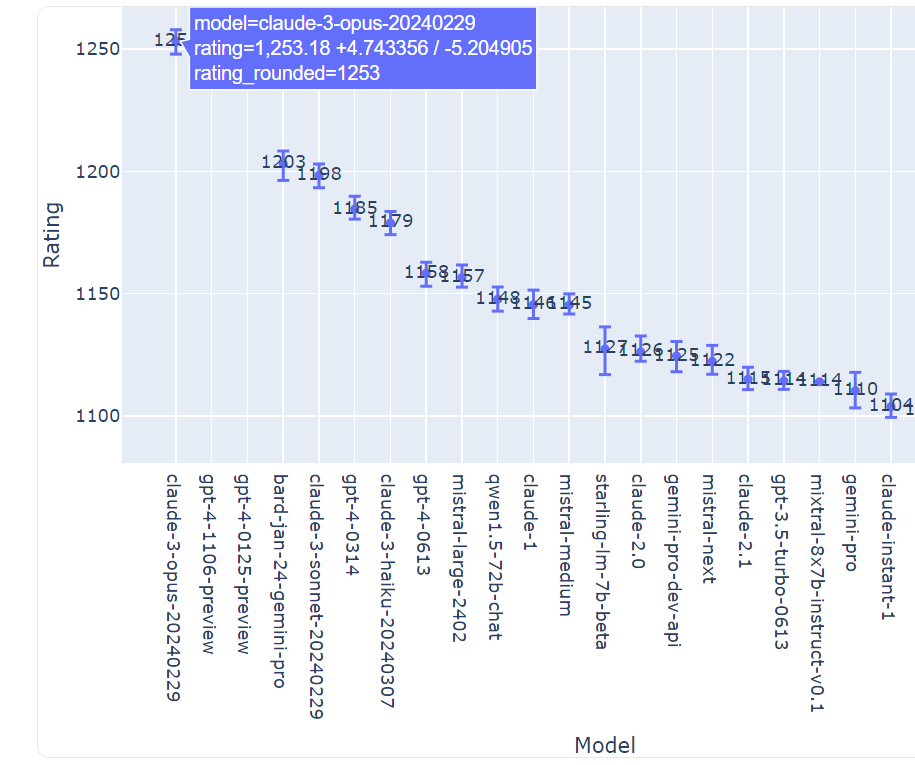
According to the latest ranking, Claude 3 Opus received a total of 33,250 votes, with the second ranked GPT-4-1106-preview receiving 54,141 votes. But getting more reviews doesn't necessarily mean being stronger. In order to rate LLM, the leaderboard adopts the Elo ranking system, which is a commonly used method in games such as chess to measure the relative strength of players compared to other players in certain competitions. After using the Elo ranking system, Claude 3 Opus achieved first place in the latest ranking with a total score of 1,253 on the confidence interval of model strength, narrowly surpassing the GPT-4-1106-preview with 1,251 points.
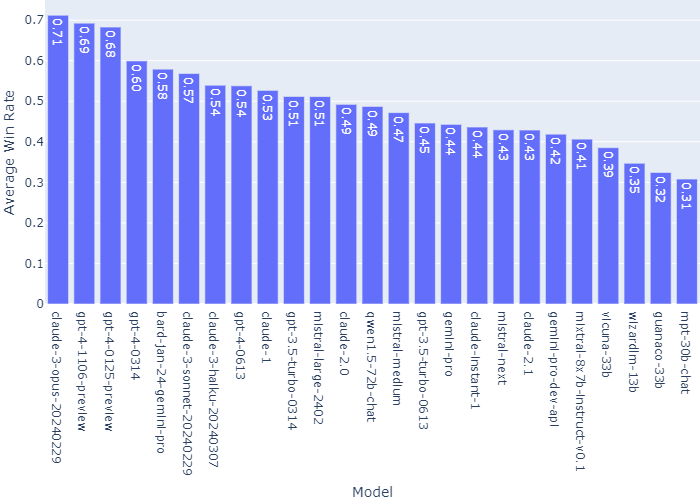
Among them, Claude 3 Opus is the only one with a win rate of over 0.7 in the term "average win rate for all other models (assuming uniform sampling and no draw)".
In the latest ranking, other LLMs that entered the top 10 include Google's Gemini Pro, Mistral large-2402, and Qwen1.5-72B Chat.With the GPT-4 losing the top spot, the Claude 3 series models all entered the top 10, and coupled with the weakest Claude 3 Haiku in the Claude 3 series defeating the GPT-4 0613, Antitopic immediately caused a sensation in the entire AI industry.
Software developer Nick Doboss bluntly stated on social media, "The king is dead. RIP GPT-4." He stated that Claude 3 Haiku's victory over GPT-4 0613 was "insane how cheap & fast it is."

Even the official LMYSY Org post stated, "Claude-3 Haiku has impressed all, even reaching GPT-4 level by our user preference! Its speed, capabilities & context length are unmatched now in the market."
·Original
Disclaimer: The views in this article are from the original Creator and do not represent the views or position of Hawk Insight. The content of the article is for reference, communication and learning only, and does not constitute investment advice. If it involves copyright issues, please contact us for deletion.












