苹果AI终于脱困:OpenELM可在移动设备自由运行!
当地时间4月24日,苹果发布了开源AI模型OpenELM,可在手机、笔记本电脑等设备上自由运行。
随着ChatGPT的横空出世,AI成为了各大科技公司的竞逐赛道之一,三星、小米等3C厂商也纷纷开始在其手机、平板等端侧推进LLM的全面应用,照片、文字和视频效果增强的热度暴涨。而苹果在很长一段时间内,都仿佛没有成功挤入AGI领域,极少透露其产品的AI功能,更倾向于依赖第三方工具的承载力。
在今年2月的财报会议上,苹果CEO Tim Cook首度透露了公司的AGI计划,并将于今年内在其软件平台(iOS、iPadOS和macOS)中实现AI技术的集成。他认为,苹果在AGI和AI领域有着巨大的机会,公司未来将继续投入AI领域的研究,并将在今年晚些时候分享该领域的工作细节。
当地时间4月24日,苹果公司在HuggingFace发布了首个“具有开源训练和推理框架的高效语言模型”模型OpenELM,配备生成文本、代码、翻译、总结摘要等功能。不仅如此,在WWDC 2024前夕,苹果还对该模型的权重和推理代码、数据集和训练日志等进行开源,另还将其神经网络库CoreNet对外开放。
据了解,OpenELM以超小规模模型为定位,配有270M、450M、1.1B和3B共4个参数规模,且每个规模都有一个预训练和指导版本。相较于微软Phi-3 Mini的38B和谷歌Gemma的20B,OpenELM的运行成本更低,手机、笔记本电脑等设备均可在脱离云服务器的情况下支持其运行。
OpenELM系列基于神经网络而设计,又称“纯解码器Transformer架构”,该架构也是微软Phi-3 Mini及其它许多LLM的基础。它还是CarperAI设计的一个开源库,旨在使用代码和自然语言中的语言模型优化搜索。其中,LLM由相互连接的构件(又称为“层”)组成,第一层负责接收并处理用户指令,对其处理后发送至下一层;在多次重复后,处理结果会输入到最后一层,最终输出响应。
因此,通过使用逐层缩放策略,OpenELM可以有效地分配Transformer模型每一层的参数,从而提高准确性。与今年2月发布的OLMo开放式LLM相比,在10B左右的参数规模下,OpenELM较OLMo在准确率方面提升了2.36%,预训练所需的token数却减少了50%。
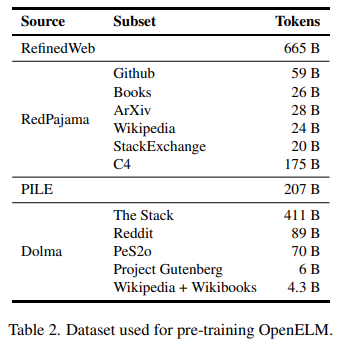
训练流程上,苹果采用了CoreNet作为训练框架,并使用了Adam优化算法进行了35万次迭代训练。与以往仅提供模型权重和推理代码并在私有数据集上进行预训练的方法不同,OpenELM选择在公开数据集上进行训练。HuggingFace网站上的资料记载,预训练数据集包括RefinedWeb、去重的PILE、RedPajama的子集和Dolma v1.6的子集,总计约1.8万亿个token。
根据该项目研究人员发布的相关论文,LLM的可重复性和透明度对于推进开放研究、确保结果的可信性以及对数据和模型偏差以及潜在风险的调查至关重要。因此,苹果还发布了将模型转换为MLX(机器学习加速器)库的代码,以便在苹果设备上进行推理和微调。

OpenELM的研究团队表示:“此次全面发布旨在增强和巩固开放研究社区,为未来的开放研究工作铺平道路。”
AI服务企业Aquant CEO兼联合创始人Shahar Chen表示:“苹果发布OpenELM是AI界的一大重点突破,提供了更为高效的AI处理功能,是计算能力有限的移动或物联网设备的理想选择。因此,该模型使从智能手机到智能家居设备的迅速决策成为可能,成功挖掘了AI在日常生活中的技术潜力。”
·原创文章
免责声明:本文观点来自原作者,不代表Hawk Insight的观点和立场。文章内容仅供参考、交流、学习,不构成投资建议。如涉及版权问题,请联系我们删除。












