この“オープンソース”モデルは、AIツールチェーンの価値分配ロジックを再構築する可能性があります。
3月25日、中国の人工知能スタートアップDeepSeekは静かに大規模な言語モデルDeepSeek-V 3 - 0 3 2 4の新世代をリリースしました。このパラメータは、Huging Faceプラットフォームにほぼ“ステルス”の姿勢で、巨大な685億に達し、すぐに業界の地震を引き起こしました。カンファレンスもホワイトペーパーもなく、完全な説明文書もないこの“控えめな”行動は、技術的ブレークスルーとビジネスモデルの二重の転覆のために、グローバルAI分野で無視できない変数になっています。
DeepSeek V 3がHugging Faceプラットフォームに登場
技術的な観点から、DeepSeek-V 3 - 0 3 2 4のイノベーションは、効率の再構築、能力の飛躍、生態系の開放性の3つの側面に反映されています。
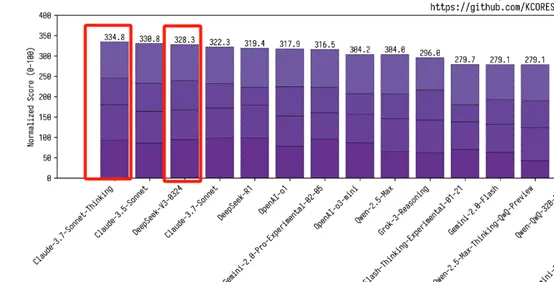
モデルは混合エキスパート(MoE)アーキテクチャを採用し、実際に実行する時に約370億パラメータのみを活性化し、4ビット量子化技術を組み合わせた後、その推論速度はM3 Ultraチップを搭載したMac Studioで毎秒20トークンに達し、ビッグモデルをデータセンター GPUクラスタの束縛から解放する。この“選択的アクティベーション”メカニズムは、ハードウェアのしきい値を90%削減するだけでなく、推論コストを類似のクローズドソースモデルと比較して数十倍削減します。例えば、API呼び出しコストはClaude 3.7 Sonnetの1/21(入力)と1/53(出力)です。パフォーマンス面では、数学(AIME評価で1 9.8%向上)、コード(LiveCode Benchで10%向上)などのコアシナリオでGPT-4.5を上回り、推論に特化したClaude 3.7 Sonnetにも匹敵し、汎用モデルとしては珍しいマルチタスクバランスを示しています。
ビジネス戦略的には、DeepSeekのMITライセンスの選択は“オープンソース活動”の一例である。シリコンバレーの巨人のコアテクノロジーに対する保守的な姿勢とは異なり、同社は開発者が自由に変更、商用モデルの重み付け、さらには蒸留による派生モデルのトレーニングを可能にしている。AnthropicがClaude Sonnetに月額20ドルのサブスクリプション料金を請求したとき、DeepSeekは限界コストゼロ戦略で中小規模の開発者を引き付け、生態学的障壁を迅速に構築しました。開発者はこのモデルを使用してサイバーパンクスタイルのウェブページのフロントエンドコードや物理シミュレーションプログラムなどの複雑なアプリケーションを生成し、その出力品質はクローズドソースの競合製品とほとんど変わらないことを示しています。この“オープンソース”モデルは、AIツールチェーンの価値分配ロジックを再構築する可能性があります。
より深い業界への影響は、DeepSeekのテクノロジーへの道がシリコンバレーが支配する“コンピューティング軍拡競争”の物語に挑戦することです。従来の大規模モデルがワンカードクラスタトレーニングと高消費電力推論インフラストラクチャに依存していたのに対し、DeepSeekはマルチ潜在的注意MLAやマルチタグ予測MTPなどのアルゴリズム最適化を通じてパフォーマンスとエネルギー効率のバランスを達成しました。
データによると、Mac Studioは200ワット未満の電力でモデルを実行し、NVIDIA GPUソリューションよりも90%少ないため、データセンターの重い資産投資に依存しているOpen AIやGoogleなどの企業にとって直接的な脅威となります。さらに注目すべきは、トレーニングコストがわずか600万ドルであり、GPT-4などのモデルの数億ドルよりもはるかに低く、この“究極のコストパフォーマンス”は中国のAI産業の非対称競争優位性を生み出す可能性があることです。
市場の反応は、この変化の破壊的な可能性を確認しました。Hugging Faceプラットフォームの立ち上げから12時間以内に、モデルは700以上の“いいね”を獲得し、分子動力学シミュレーションからゲームエンジン開発まで、開発者コミュニティは多数のユースケースを生み出し、強力な技術一般化能力を示しました。機関投資家はAIインフラストラクチャ投資ロジックを再評価し始めています。コンシューマグレードのハードウェアがトップモデルを展開できるようになれば、従来のクラウドベンダーのGPUレンタルビジネスの評価モデルは再構築に直面するでしょう。
DeepSeek R 2はまだ遠いですか?
市場筋によると、DeepSeekの次世代AIモデルDeepSeek-R 2も公開される予定です。

メディアの報道によると、DeepSeekは次世代AIモデルR 2を早期にリリースする予定です。同社は当初5月のローンチを予定していたが、できるだけ早くローンチしようとしている。DeepSeekは、新しいモデルはプログラミング能力と多言語推論の面で改善されると述べた。
リークされた技術文書によると、R2は動的にスパースに活性化されるハイブリッドエキスパートシステム(MoE)を採用しており、128個のドメインエキスパートモジュールの協調によって、1回の推論で4-8個のエキスパートネットワークのみを活性化させ、従来の高密度モデルよりもエネルギー消費を70%削減しています。さらに重要なことに、知識蒸留補償メカニズムは、パラメータ圧縮による機能的去勢の問題を解決し、専門家が眠っている間にコア特徴を自動的に抽出し、法的テキストの翻訳エラー率を0.3%未満にします。

この“馬が走り、馬が草を食べない”という技術ルートは、企業顧客の最大の需要を満たしています。多国籍金融機関のCTOは、R 1モデルを使用して信用リスク評価を処理する際に、1回の分析コストを3.2ドルから0.8ドルに押し下げ、R 2の導入により限界コストをさらに0.2ドルの範囲に押し上げる可能性があることを明らかにしました。
インドのテクノロジーサービスプロバイダー Zensarの最高執行責任者であるVijayasimha Alilughatta氏は、“DeepSeekのR 2モデルのリリースは、AI業界にとって重要な瞬間になる可能性があります。DeepSeekの費用対効果の高いAIモデルの構築に成功したことは、グローバル企業が研究開発を加速し、現在の少数の支配的な企業の独占を打破することを可能にします。”






