DeepSeek爆火:硅谷AI发展范式思维或被打破
DeepSeek-R1在推理能力上已超越Llama 4,而训练成本仅相当于Meta单个高管年薪。
DeepSeek火了。
2025年1月,中国初创企业深度求索(DeepSeek)连续发布了DeepSeek-V3和DeepSeek-R1两款大模型,掀起行业巨浪。
这家成立于2023年的公司的大模型产品,不仅以接近OpenAI的性能指标刷新行业认知,更以550万美元的超低训练成本颠覆了硅谷对AI研发投入的固有逻辑。根据AI数据服务领域头部企业Scale AI的测试报告,DeepSeek-V3在多项核心指标上已与美国顶尖模型比肩。
1月24日,Alexander Wang在接受专访时直言,这家中国企业的突破揭示了"当硅谷沉迷于资本狂欢时,东方工程师正以更精密的系统优化能力改写游戏规则"。这种观点在匿名职场平台Teamblind上得到侧面印证:某Meta工程师发帖披露,公司高层对DeepSeek的技术路径展开紧急研究,其开源模型DeepSeek-R1在推理能力上已超越Llama 4(Meta开发的生成式AI模型),而训练成本仅相当于Meta单个高管年薪,这令每年投入数十亿美元研发预算的硅谷巨头陷入战略焦虑。
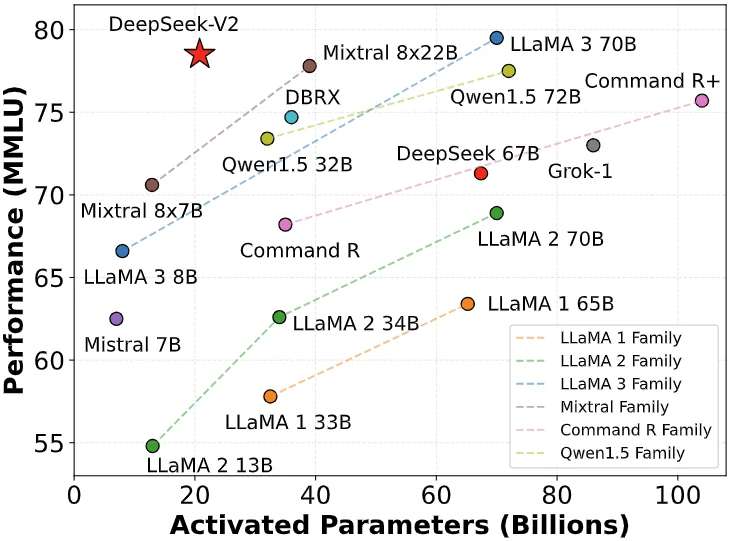
技术细节显示,DeepSeek-V3于2023年12月27日开源后,即在LMSys Chatbot Arena排行榜斩获开源模型首位,其综合性能超越Llama 2-70B、Falcon-180B等国际知名模型。更引人注目的是,该模型在单位token成本上较同类产品降低80%,这种成本效益在2024年1月20日发布的DeepSeek-R1上得到进一步强化。
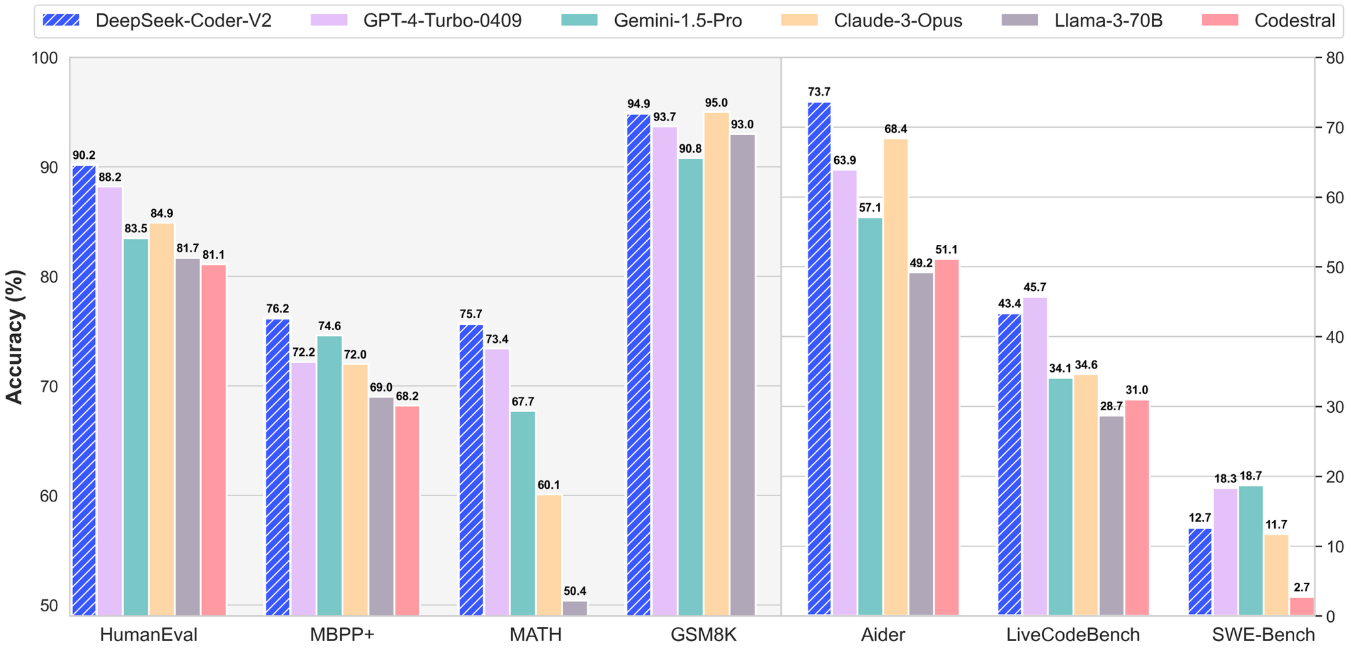
据斯坦福大学AI实验室的独立评测,R1模型在代码生成、数学推理等高难度任务中超越GPT-4 Turbo,其风格控制能力与Anthropic的顶尖闭源模型o1并列榜首,而API调用成本仅为后者的3%。这种"性能跃升与成本压缩同步实现"的技术特征,直接动摇了行业信奉的"算力规模决定论"。
产业影响在资本市场迅速显现。
1月24日,英伟达股价单日下挫3.12%,创下三个月来最大跌幅,市场担忧中国AI企业的算力优化能力将削弱对尖端芯片的依赖。这种情绪与OpenAI最大机构投资者微软近期表态形成共振——其首席技术官凯文·斯科特在达沃斯论坛坦言,当前AI竞赛已从单纯追求参数量转向"算法创新与工程效率的复合竞争"。
诺奖得主、"深度学习之父"杰弗里·辛顿(Geoffrey Hinton)在近期访谈中进一步指出,中国庞大的STEM人才储备(每年约500万毕业生,远超美国的80万)正转化为工程实践优势,这种系统性能力可能使技术封锁策略适得其反。
硅谷风险投资界对此轮冲击的反应呈现分化态势。A16z(硅谷顶级风投,管理资产超350亿美元)创始人马克·安德森(Marc Andreessen)将DeepSeek-R1誉为"开源社区的里程碑",而红杉资本分析师则警告,若行业头部企业维持现有资本消耗速度(美国AI公司年硬件支出预计2028年达5,000亿美元),投资回报周期将面临严峻考验。
在产业深层,这场冲击波正引发对AI发展范式的根本性质疑。斯坦福大学与Epoch AI(专注AI技术预测的研究机构)联合研究曾预测,到2027年顶尖模型的训练成本将突破10亿美元门槛。
![]()
但深度求索的实践表明,通过改进MoE(混合专家)架构、优化数据清洗流程、创新分布式训练策略,完全可能在有限预算内实现性能突破。这种"精算式创新"对Meta、Google等依赖海量资源的科技巨头构成双重挑战:既要在技术路线上应对后发者的突袭,又需向投资者证明千亿级投入的必要性。正如华尔街分析师"THE SHORT BEAR"在X平台发出的警示:"当5,500万美元就能打造出顶尖模型,整个AI产业的估值体系都需要重构。"
·原创文章
免责声明:本文观点来自原作者,不代表Hawk Insight的观点和立场。文章内容仅供参考、交流、学习,不构成投资建议。如涉及版权问题,请联系我们删除。











