AI Startup Cerebras Takes on NVIDIA with its 20-Times-Faster AI Solution
AI startup Cerebras has announced the launch of Cerebras Inference, the world’s fastest AI inference solution, which is 20 times faster than solutions based on NVIDIA’s latest generation Hopper GPUs in today’s hyperscale clouds.
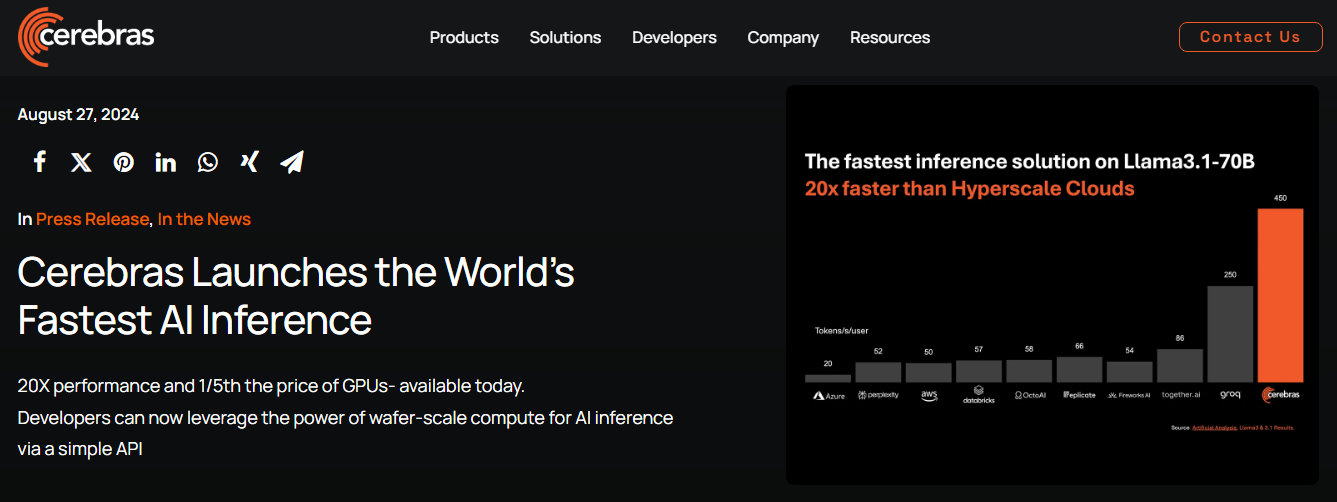
On August 28, local time, AI startup Cerebras announced the launch of Cerebras Inference, which is said to be the world's fastest AI inference solution.
As chatbots and other AIGC applications become more and more popular, inference services have become the fastest growing part of AI computing, accounting for about 40% of all AI workloads in the entire cloud.
Cerebras is a manufacturer specializing in the production of powerful computer chips for AI and HPC and their workloads. According to it, Cerebras Inference uses the Cerebras CS-3 system and its Wafer Scale Engine 3 (WSE-3) AI processor, the former has 7,000 times the memory bandwidth of NVIDIA H100, and the latter has 52 times the number of cores of a single NVIDIA H100.
The company also claimed: "Cerebras Inference provides 1,800 tokens per second for Llama 3.18B and 450 tokens per second for Llama 3.170B, which is 20 times faster than solutions based on NVIDIA's latest generation Hopper GPUs in hyperscale clouds such as Microsoft Azure."
With record-breaking performance, industry-leading pricing and open API access, Cerebras Inference sets a new standard for open LLM development and deployment. Andrew Feldman, founder and CEO of Cerebras, believes that this ultra-high-speed AI reasoning will bring huge opportunities for AI adoption.
It is understood that Cerebras Inference has the following three tiers:
- The free tier provides free API access and considerable usage limits for all log-ins.
- The developer tier is designed for flexible serverless deployment and provides users with endpoints that are fully compatible with OpenAI Chat Completions' API, making it easy to build the next generation of AI applications without compromising speed or cost.
- The enterprise tier provides fine-tuned models, customized service level agreements and dedicated support. Enterprises can access Cerebras Inference through a Cerebras-managed private cloud or on-premises, suitable for sustained workloads.
In addition to ultra-high performance, the solution is also priced much lower than GPU cloud, with Llama 3.1 8B and 70B models priced at 10 cents and 60 cents per million tokens, respectively, providing at least 100 times the price-performance ratio for AI workloads.
"Cerebras is leading in our AI inference benchmarks," said Micah Hill-Smith, co-founder and CEO of Artificial Analysis. "For the Llama 3.1 8B and 70B AI models, Cerebras delivered an order of magnitude faster speed than GPU-based solutions, setting a new benchmark record for tokens output per second."

In addition to inference services, Cerebras has announced several strategic partnerships to provide customers with the specialized tools they need to accelerate AI development, including LangChain, LlamaIndex, Docker, Weights&Biases, and AgentOps.
Not only that, Cerebras also submitted an IPO application earlier this month and is expected to go public in the second half of this year. In addition, the company recently appointed two new board members: Glenda Dorchak, who has served as an executive at IBM, Intel, and Telefonica, and Paul Auvil, the former chief financial officer of VMware and Proofpoint.
Cerebras is not only a leader in AI computing, but also plays an important role in multiple industries such as healthcare, energy, government, scientific computing, and financial services. By continuously advancing technological innovation, Cerebras is helping organizations in various fields meet complex AI challenges.
·Original
Disclaimer: The views in this article are from the original Creator and do not represent the views or position of Hawk Insight. The content of the article is for reference, communication and learning only, and does not constitute investment advice. If it involves copyright issues, please contact us for deletion.












