比英伟达快20倍?Cerebras推出全球最快AI方案!
AI初创公司Cerebras宣布推出世界上最快的AI推理解决方案Cerebras Inference,速度比当今超大规模云中基于英伟达最新一代Hopper GPU的解决方案快20倍。
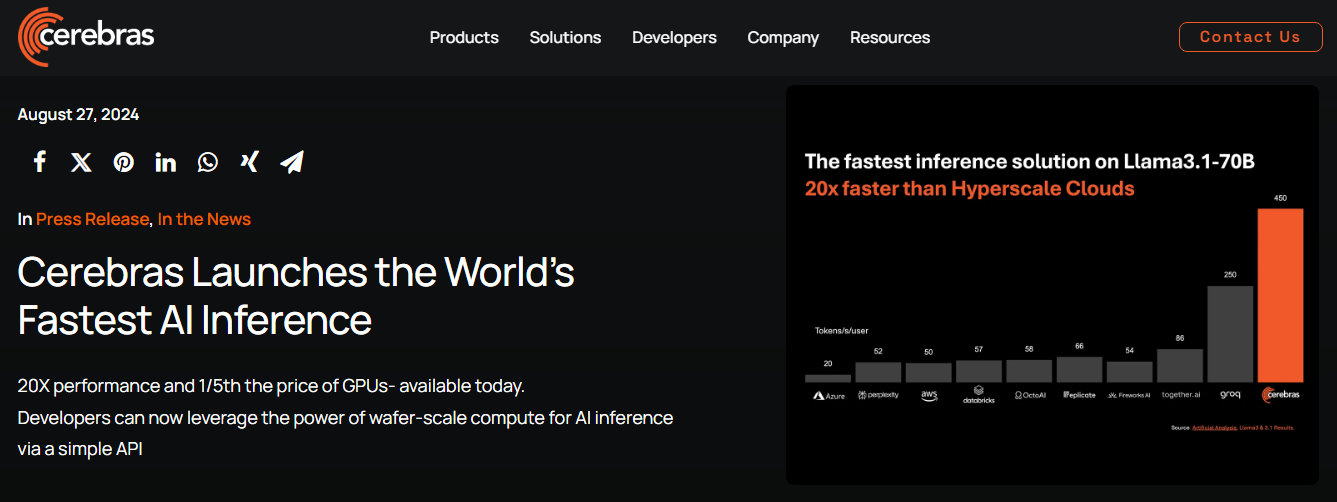
当地时间8月28日,AI初创公司Cerebra宣布推出Cerebras Inference,据称是目前世界上最快的AI推理解决方案。
随着聊天机器人和其他AIGC应用程序的热度愈来愈高,推理服务成为了AI计算中增长最快的部分,约占整个云端所有AI工作负载的40%左右。
Cerebras是一家专门生产用于AI和HPC及其工作负载的强大计算机芯片的生产商。据其介绍,Cerebras Inference使用了Cerebras CS-3系统及其Wafer Scale Engine 3(WSE-3)AI处理器,前者的内存带宽是英伟达H100的7,000倍,而后者的内核数量是单个英伟达H100的52倍。
该公司还声称:“Cerebras Inference为Llama 3.18B每秒提供1,800个token,为Llama 3.170B每秒提供450个token,比微软Azure等超大规模云中基于英伟达最新一代Hopper GPU的解决方案快20倍。”
凭借创纪录的性能、业界领先的定价和开放的API访问,Cerebras Inference 为开放的LLM开发和部署设定了新标准。Cerebras的创始人兼首席执行官Andrew Feldman认为,这种超高速AI推理将为AI的采用带来巨大机遇。
据了解,Cerebras Inference共有以下三个层级:
- 免费层为所有登录者提供免费的API访问和可观的使用限制。
- 开发者层专为灵活的无服务器部署而设计,为用户提供与OpenAI Chat Completions的API完全兼容的端点,便于构建下一代AI应用程序,而不会对速度或成本造成影响。
- 企业层提供微调模型、定制服务级别协议和专门支持。企业可以通过Cerebras管理的私有云或客户场所访问Cerebras Inference,适合持续的工作负载。
除了超高性能以外,该方案的定价也比GPU云低得多,Llama 3.1 8B和70B模型的定价分别为每百万token 10美分和60美分,可为AI工作负载提供至少100倍的性价比。
Artificial Analysis联合创始人兼首席执行官Micah Hill-Smith表示:“Cerebras在我们的AI推理基准测试中处于领先地位。对于Llama 3.18B和70B AI模型,Cerebras提供的速度比基于GPU的解决方案快一个数量级,每秒输出的token创下了基准测试的新纪录。”

除了推理服务外,Cerebras还宣布了多项战略合作伙伴关系,为客户提供加速AI开发所需的专用工具,合作伙伴包括LangChain、LlamaIndex、Docker、Weights&Biases和AgentOps等。
不仅如此,Cerebras在本月初还提交了IPO申请,预计将于今年下半年上市。另外,该公司最近还认命了两名新的董事会成员:曾在IBM、英特尔和西班牙电信担任高管的Glenda Dorchak,以及VMware和Proofpoint的前首席财务官Paul Auvil。
Cerebras不仅在AI计算领域中引领潮流,还在医疗、能源、政府、科学计算和金融服务等多个行业中扮演着重要角色。通过不断推进技术创新,Cerebras正在帮助各个领域的组织应对复杂的AI挑战。
·原创文章
免责声明:本文观点来自原作者,不代表Hawk Insight的观点和立场。文章内容仅供参考、交流、学习,不构成投资建议。如涉及版权问题,请联系我们删除。












