DeepSeek低调发布V3模型,R2还会远吗?
这种“开源即获客”的模式,或将重构AI工具链的价值分配逻辑。
3月25日,中国人工智能初创公司DeepSeek悄然发布新一代大语言模型DeepSeek-V3-0324,这一参数规模达6850亿的庞然大物,以近乎“隐身”的姿态登陆Hugging Face平台,却迅速引发行业地震。这场没有发布会、没有白皮书、甚至没有完整说明文档的“低调”行动,反而因其技术突破与商业模式的双重颠覆,成为全球AI领域不可忽视的变量。
DeepSeek V3 低调登陆Hugging Face平台
从技术层面看,DeepSeek-V3-0324的革新体现在三个维度:效率重构、能力跃迁与生态开放。
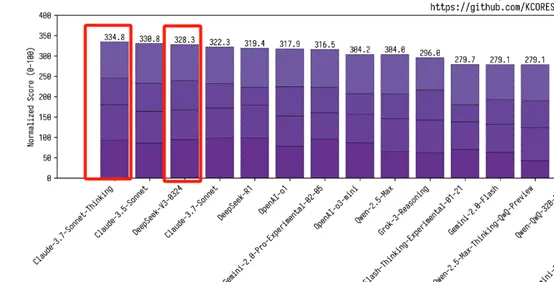
模型采用混合专家(MoE)架构,实际运行时仅激活约370亿参数,结合4位量化技术后,其推理速度在配备M3 Ultra芯片的Mac Studio上达到每秒20个token,将大模型从数据中心GPU集群的桎梏中解放。这种“选择性激活”机制不仅降低90%的硬件门槛,更使推理成本较同类闭源模型降低数十倍——例如,其API调用成本仅为Claude 3.7 Sonnet的1/21(输入)和1/53(输出)。性能方面,模型在数学(AIME评测提升19.8%)、代码(LiveCodeBench提升10%)等核心场景超越GPT-4.5,甚至逼近专精推理的Claude 3.7 Sonnet,展现出通用模型罕见的多任务均衡性。
商业策略上,DeepSeek的MIT许可证选择堪称“开源激进主义”的典范。不同于硅谷巨头对核心技术的保守姿态,该公司允许开发者自由修改、商用模型权重,甚至通过蒸馏训练衍生模型。这种开放性直接冲击现有市场格局:当Anthropic对Claude Sonnet收取每月20美元订阅费时,DeepSeek以零边际成本策略吸引中小开发者,快速构建生态壁垒。已有案例显示,开发者利用该模型生成赛博朋克风格网页前端代码、物理模拟程序等高复杂度应用,其输出质量与闭源竞品几无差异。这种“开源即获客”的模式,或将重构AI工具链的价值分配逻辑。
更深层的行业影响在于,DeepSeek的技术路径挑战了硅谷主导的“算力军备竞赛”叙事。传统大模型依赖万卡集群训练与高功耗推理基础设施,而DeepSeek通过算法优化(如多头潜在注意力MLA与多标记预测MTP)实现性能与能效的平衡。
数据显示,Mac Studio运行该模型的功耗不足200瓦,较英伟达GPU方案降低90%,这对依赖数据中心重资产投入的OpenAI、Google等企业构成直接威胁。更值得关注的是,其训练成本仅600万美元,远低于GPT-4等模型的数亿美元投入,这种“极致性价比”可能催生中国AI产业的非对称竞争优势。
市场反应验证了这场变革的颠覆性潜力——Hugging Face平台上线12小时内,模型即获700余次点赞,开发者社区涌现大量应用案例,从分子动力学模拟到游戏引擎开发,显示出极强的技术泛化能力。机构投资者开始重新评估AI基础设施投资逻辑:若消费级硬件即可部署顶尖模型,传统云计算厂商的GPU租赁业务估值模型将面临重构。
DeepSeek R2还会远吗?
市场消息称,DeepSeek下一代AI模型DeepSeek-R2也即将和大众见面。

据媒体报道,DeepSeek计划提前发布其新一代AI模型R2。该公司最初计划在5月推出,但目前正在努力尽快推出。DeepSeek表示,新模型将在编程能力和多语言推理方面有所提升。
根据泄露的技术文档,R2采用动态稀疏激活的混合专家系统(MoE),通过128个领域专家模块的协同,在单次推理中仅激活4-8个专家网络,这使得其能耗较传统密集模型降低70%。更关键的是,其知识蒸馏补偿机制解决了参数压缩导致的功能阉割问题,能够在专家休眠时自动提取核心特征,确保法律文本翻译错误率低于0.3%。

这种“既要马儿跑,又要马儿不吃草”的技术路线,恰好击中了企业客户的最大需求——某跨国金融机构的CTO透露,他们使用R1模型处理信贷风险评估时,已将单次分析成本从3.2美元压至0.8美元,而R2的推出可能进一步将边际成本推向0.2美元区间。
印度技术服务提供商Zensar的首席运营官Vijayasimha Alilughatta表示:“DeepSeek的R2模型发布可能会成为AI行业的一个关键时刻。DeepSeek成功打造了具有高性价比的AI模型,将促使全球公司加速研发进程,打破目前由几家主导企业垄断的格局。”
·原创文章
免责声明:本文观点来自原作者,不代表Hawk Insight的观点和立场。文章内容仅供参考、交流、学习,不构成投资建议。如涉及版权问题,请联系我们删除。






