This "open source is getting customers" model may restructure the value allocation logic of the AI tool chain.
On March 25, China's artificial intelligence startup DeepSeek quietly released a new generation of big language model DeepSeek-V3 -0324. This giant with a parameter scale of 685 billion landed on the Hugging Face platform in a near-invisible "manner, but quickly triggered an industry earthquake.This "low-key" operation without a press conference, no white paper, or even a complete explanatory document has become a variable that cannot be ignored in the global AI field due to its technological breakthroughs and double subversion of the business model.
DeepSeek V3 launches Hugging Face platform low-key
From a technical perspective, the innovation of DeepSeek-V3-0324 is reflected in three dimensions: efficiency reconstruction, capability transition and ecological openness.
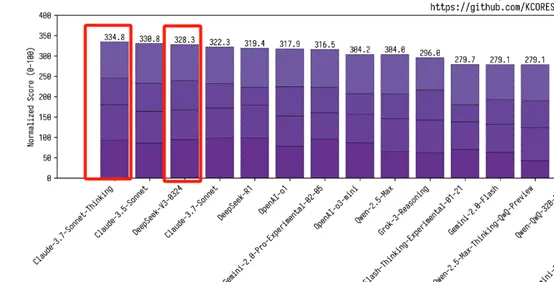
The model adopts a Hybrid Expert (MoE) architecture, and only about 37 billion parameters are activated during actual operation. Combined with 4-bit quantization technology, its inference speed reaches 20 tokens per second on Mac Studio equipped with M3 Ultra chip, liberating the large model from the shackles of data center GPU clusters.This "selective activation" mechanism not only reduces the hardware threshold by 90%, but also reduces the inference cost by tens of times compared to similar closed-source models-for example, its API call cost is only 1/21 (input) and 1/53 (output) of Claude 3.7 Sonnet.In terms of performance, the model surpasses GPT-4.5 in core scenarios such as mathematics (AIME evaluation improved by 19.8%) and code (LiveCodeBench improved by 10%), and even approaches Claude 3.7 Sonnet, which specializes in reasoning, demonstrating the multi-tasking balance that is rare for universal models.
In terms of business strategy, DeepSeek's MIT license choice is a model of "open source activism."Unlike Silicon Valley giants 'conservative attitude towards core technologies, the company allows developers to freely modify, commercialize model weights, and even derive models through distillation training.This openness directly impacts the existing market structure: when Anthropic charged Claude Sonnet a monthly subscription fee of US$20, DeepSeek used a zero-marginal-cost strategy to attract small and medium-sized developers and quickly built ecological barriers.Existing cases have shown that developers use this model to generate high-complexity applications such as cyberpunk-style web front-end code and physical simulation programs, and the output quality is almost the same as closed-source competing products.This "open source is getting customers" model may restructure the value allocation logic of the AI tool chain.InvalidParameterValue
The deeper industry impact is that DeepSeek's technology path challenges the Silicon Valley dominated narrative of the "computing power arms race".Traditional large models rely on Wanka cluster training and high-power inference infrastructure, while DeepSeek achieves a balance between performance and energy efficiency through algorithm optimizations such as multi-head potential attention MLA and multi-tag prediction MTP.
Data shows that Mac Studio consumes less than 200 watts of power to run this model, which is 90% lower than the NVIDIA GPU solution. This poses a direct threat to companies such as OpenAI and Google that rely on heavy asset investment in the data center.What is more noteworthy is that its training cost is only US$6 million, which is far lower than the hundreds of millions of dollars invested in models such as GPT-4. This "extreme cost performance" may give rise to asymmetric competitive advantages in China's AI industry.InvalidParameterValue
The market reaction verified the disruptive potential of this change-within 12 hours of the launch of the Hugging Face platform, the model received more than 700 likes, and a large number of application cases emerged in the developer community, ranging from molecular dynamics simulation to game engine development. Strong technical generalization capabilities.Institutional investors are beginning to reassess the investment logic of AI infrastructure: If consumer-grade hardware can deploy top-notch models, the valuation model of traditional cloud computing vendors 'GPU leasing business will face restructuring.
Will DeepSeek R2 be far behind?
According to market news, DeepSeek's next-generation AI model DeepSeek-R2 will also be available to the public.

According to media reports, DeepSeek plans to release its new generation AI model R2 in advance.The company originally planned to launch in May, but is currently working to launch it as soon as possible.DeepSeek said the new model will improve programming capabilities and multilingual reasoning.
According to leaked technical documents, R2 uses a dynamically sparsely activated hybrid expert system (MoE). Through the collaboration of 128 domain expert modules, only 4-8 expert networks are activated in a single inference, which makes its energy consumption less than traditional intensive models. 70%.More importantly, its knowledge distillation compensation mechanism solves the problem of functional castration caused by parameter compression, and can automatically extract core features while experts are dormant, ensuring that the legal text translation error rate is less than 0.3%.

This technical route of "not only running but also not eating grass" just hits the biggest demand of corporate customers-the CTO of a multinational financial institution revealed that when they use the R1 model to process credit risk assessment, the cost of a single analysis has been reduced from US$3.2 to US$0.8, and the launch of R2 may further push the marginal cost to the US$0.2 range.
Vijayasimha Alilughatta, chief operating officer of Indian technology service provider Zensar, said: "DeepSeek's R2 model release could become a critical moment for the AI industry.DeepSeek has successfully created a cost-effective AI model, which will prompt global companies to accelerate their research and development processes and break the current monopoly of several leading companies.”






