Another AI product "fire out of the circle"! Groq response speed amazing self-developed LPU or can threaten Nvidia
On February 19, Groq, an AI start-up in Silicon Valley, opened a free trial of its own products.。According to user tests, Groq generates nearly 500 tokens per second。
There is another big news in AI circle.。
On February 19, Groq, an AI start-up in Silicon Valley, opened a free trial of its own products.。Many users expressed shock after the trial。
GroqAmazing response speed
The most shocking thing is that Groq's response speed is so fast.。According to user tests, Groq generates nearly 500 tokens per second。
From the video we can more intuitively feel how amazing this response speed, directly crush ChatGPT that word-by-word answer generation chat robot!
This fast response speed is due to the team behind Groq developing their own custom application-specific integrated circuit (ASIC) chips for large language models (LLMs).。In contrast, the public version of the model, ChatGPT-3.5 can generate about 40 tokens per second。
In general, AI workloads fall into two distinct categories: training and inference。Although training requires a lot of computation and memory capacity, access speed is not focused on the object, reasoning is different。Through inference, the AI model must run very fast in order to provide as many tokens as possible to the end user, so as to provide users with answers faster。
From this perspective, Groq is an "inference engine," not a chatbot like ChatGPT, Gemini, or Musk's Grok.。Groq can help these chatbots run very fast, but won't completely replace them。On Groq's website, users can test different chatbots and see and compare how fast they are running with Groq。
According to third-party tests released by Artificial Analysis last week, Groq generates 247 tokens per second, while Microsoft generates 18 tokens per second.。This means that if ChatGPT runs on Groq's chip, it can run more than 13 times faster。
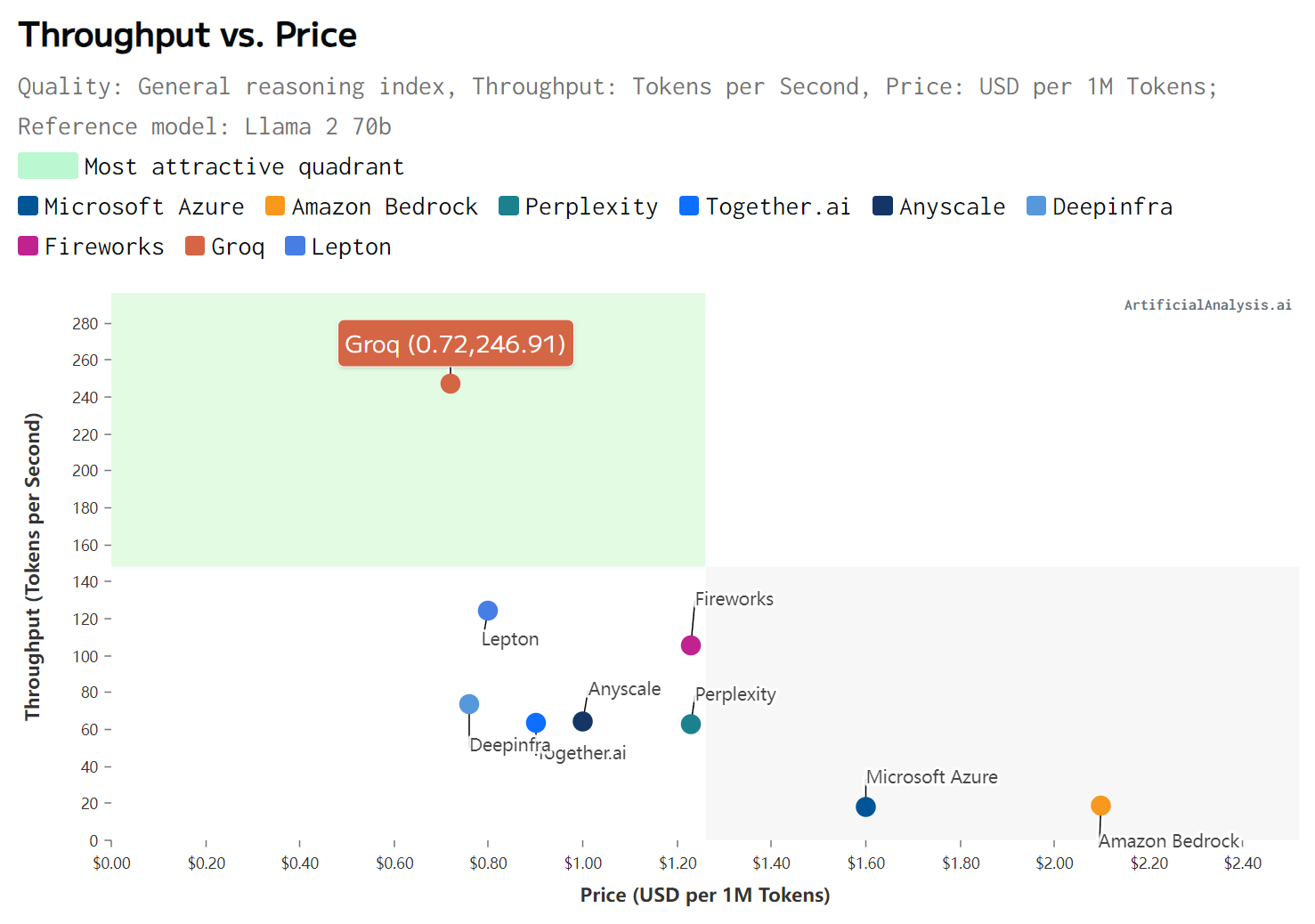
Artificial intelligence chatbots such as ChatGPT, Gemini, and Grok would also be more beneficial to AI development if they were faster.。One of the pain points of current artificial intelligence chatbots is the delay.。Google recently showed off a video related to Gemini, which allows for real-time, multi-modal conversations, although officials say the video has been edited, accelerated。But as Grok speeds up, the effect of the video may later become a reality.。
GroqWill threaten chip makers such as Nvidia?
It is also worth noting that the company that developed Groq, Groq Inc..It also says that it has created the first language processing unit (LPU) to run the model.。According to the official introduction, the LPU inference engine is a new type of end-to-end processing unit system that can provide the fastest inference for compute-intensive applications with sequential components, such as LLM。

Prior to joining Groq, founder and CEO Jonathan Ross was co-founder of Google's Artificial Intelligence Chips division, which produces cutting-edge chips for training AI models.。With LPU, Groq bypasses two LLM bottlenecks encountered by GPUs and CPUs: compute density and memory bandwidth, according to Ross.。
In terms of LLM, LPU has more powerful computing power than GPU and CPU。This reduces the computation time per word, allowing faster generation of text sequences。In addition, eliminating external memory bottlenecks allows the LPU inference engine to provide higher performance on LLMs, which can be orders of magnitude higher than GPUs。
Groq LPU has massive concurrency with 80 TB / s bandwidth and 230 MB local SRAM capacity。All of this together provides excellent performance for Groq。According to the LLMPerf leaderboard, Groq LPU beats GPU-based cloud providers in reasoning LLM Llama in configurations of 7 to 70 billion parameters。In terms of tokens throughput (output) and time (delay) of the first tokens, Groq is in a leading position, achieving the highest throughput and the second lowest delay。
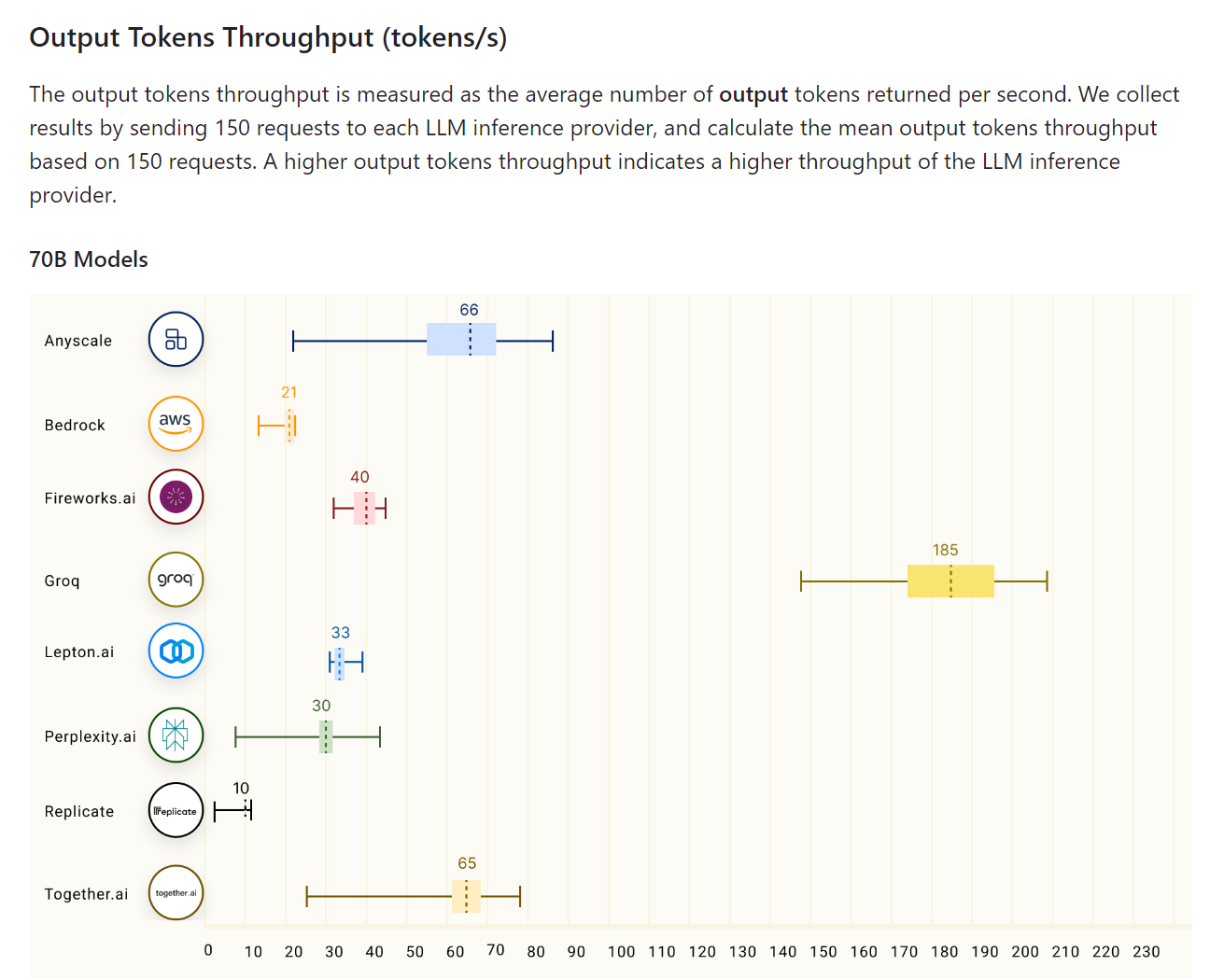
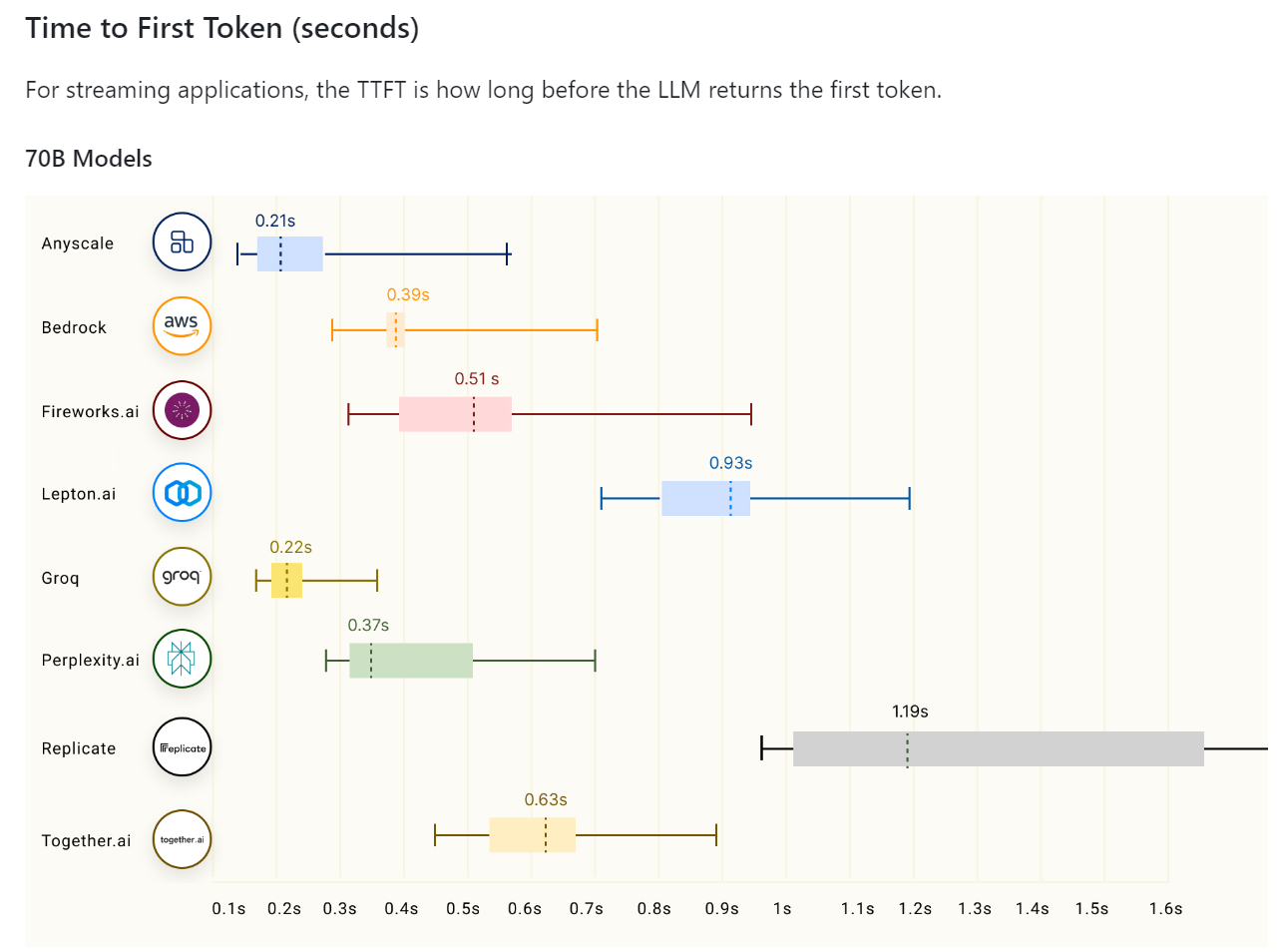
Once fast inference chips like Groq's LPU become more common, slow chatbots will be phased out。
For nearly a year, Nvidia's GPUs have been seen as the industry benchmark for running AI models, and Nvidia's GPUs have become increasingly scarce and expensive under the AI boom.。Now early results suggest that LPU may beat GPUs in AI model training and become a replacement for Nvidia A100 and H100 chips。
While it's still a question of whether LPU will be widely adopted by the industry, its demonstrated ultra-high inference performance has more or less challenged the position of GPU providers such as Nvidia, AMD and Intel.。
Nowadays, AI chips are getting more and more attention from the industry. Not only are traditional chip manufacturers paying attention, but other technology companies are also showing high interest in AI chips.。Major AI companies, including OpenAI, are looking to develop in-house chips to reduce their reliance on chipmakers like Nvidia.。It follows reports that OpenAI CEO Sam Altman has traveled to places like the Middle East to find investors and expects to raise trillions of dollars to develop his own chips to overcome problems with product scaling.。
·Original
Disclaimer: The views in this article are from the original Creator and do not represent the views or position of Hawk Insight. The content of the article is for reference, communication and learning only, and does not constitute investment advice. If it involves copyright issues, please contact us for deletion.












